
Before objects can be made persistent the database files have to be created on your disk drive and the database has to be opened. Database can be created either on your local file system or on a shared network drive. To create the database use the following expression:
db := OmniBase createOn: 'c:\temp\MyDB'.
After evaluating this expression there will be a database created in the directory MyDB. If the directory MyDB does not already exist it will be automatically created. If there already exists a database in the directory an exception will be signaled.
Now after the database is created you can already use the database or close it with:
db close.
The database can later be opened simply using the following expression:
db := OmniBase openOn: 'c:\temp\MyDB'.
The method #openOn: answers object which represents the opened database session. With the session you can for example find out how many users are currently working with the database by evaluating:
db numberOfClients
or you can begin a transaction for storing and retrieving objects from the database. How all this is done is explained in the following chapters so when you see that we are using the variable db you know that it refers to the opened database session.
First thing one has to remember about object databases is that every time an object is loaded or stored into the database this has to happen inside a transaction. Transaction can be regarded as a unit of work. It transforms the database from one consistent state to another and is seen by every other user as one atomic operation. And once the transaction completes it is either completely done or nothing happens at all. From user's point of view an example of a transaction could be editing a person's data. First when the transaction begins the person object is loaded from the database, locked and displayed in a dialog window. Then the user begins changing the data and when he is done he clicks either the Ok button or the Cancel button. If the Cancel button was clicked the transaction is committed otherwise it is aborted.
The basic scenario for accessing the database is:
1. begin transaction
2. get, create or change persistent objects
3. commit or abort transaction
In OmniBase this can be done like this:
[ OrderedCollection newPersistent add: 'string object'; add: 1; add: Date today ] evaluateAndCommitIn: db newTransaction.
As you can see in this example we have created a new persistent OrderedCollection and added some objects to it. Since the block was evaluated with message #evaluateAndCommitIn: the system knew in which transaction the database is being accessed. After the block is evaluated the transaction is committed. When transaction commits the newly created persistent OrderedCollection is stored into the database. Now we could store any other Smalltalk object into the database the same way that as we have stored the collection in the example above.
In the example above the transaction is used implicitly inside the block. The same can be done by referencing the transaction explicitly like this:
txn := db newTransaction. txn makePersistent: (OrderedCollection new add: 'string object'; add: 1; add: Date today; yourself). txn commit.
The only difference between these two ways is that in the first case the transaction would be automatically aborted if an error occurs during the evaluation of the block. In the later case we would have to use #ifCurtailed: to do it separately.
Now we have seen how to make objects persistent but once the object is already in the database how do we get it back? Well in the example above there is no way to get it back since we have lost all references to it. And if there is no one referencing the object it will get garbage collected during the next database garbage collection (the same as it happens in memory with every transient object). This is where the database root object comes into action. So let us now do it right:
[ OmniBase root at: 'test' put: (OrderedCollection newPersistent add: 'string object'; add: 1; add: Date today; yourself) ] evaluateAndCommitIn: db newTransaction.
Database root is like an entry point into the database. Initially when you create the database root is an instance of a Dictionary (ODBPeristentDictionary which is a subclass of Dictionary to be exact). Every persistent object is either directly or indirectly referenced by the database root. This is also called persistence by reachability. So to fetch an object from the database you need to know how to navigate through all the persistent objects to get it. In our case we can later get the stored collection back just with:
[ coll := OmniBase root at: 'test'. "now let's change the persistent collection" coll add: 'Another object'. "notify transaction that the collection has been changed and that it has to be written into the database" coll markDirty ] evaluateAndCommitIn: db newTransaction.
Also note from the example above that we had to explicitly notify the transaction that the persistent collection is changed. Without sending #markDirty no change would be written into the database upon transaction commit. This is necessary since there is no notification mechanism implemented in the usual OrderedCollection which would notify transaction that an element was added to the collection. This is also the reason why the database root is an instance of a class ODBPersistentDictionary which automatically notifies the transaction each time an association is added, changed of removed.
In our example we have placed the collection directly in the database root. Usually the we do not do it like this but use more complex strategies for storing object. The database root would therefore contain only top-level objects like dictionaries of all persons, contracts etc. To get to a particular person we would first get dictionary of all persons and later get the person itself. For example to fetch a person who has got id number 343 we would use:
person := (db newTransaction root at: 'persons') at: 343.
From here on we would navigate through object relations to get person's contracts, addresses, etc. depending on our object model.
When an object is made persistent in OmniBase this means that at some point the object will have to be serialized into a series of bytes which can then be stored onto the underlying file system. Because every object can reference any number of other Smalltalk objects it somehow has to be determined which objects will be serialized together and which should be serialized separately. Therefore when we say persistent object we really should be saying a cluster of objects that are serialized together and are being given an object identifier - OID. This can best be shown on the following example:
[ | coll1 coll2 str | coll1 := OrderedCollection new. coll2 := OrderedCollection new. str := 'This is a string'. coll1 add: str. coll2 add: str. OmniBase root at: 'one' put: coll1. OmniBase root at: 'two' put: coll2. ] evaluateAndCommitIn: db newTransaction. [ | coll1 coll2 | coll1 := OmniBase root at: 'one'. coll2 := OmniBase root at: 'two'. coll1 first isIdenticalTo: coll2 first ] evaluateIn: db newTransaction.
Evaluate the example above with 'Display It' and you will see that it will evaluate to false regardless of the fact that both collections were referencing the identical string object when we have saved them in a block that executed before. Now let us make a string persistent and evaluate the slightly changed example again:
[ | coll1 coll2 str | coll1 := OrderedCollection new. coll2 := OrderedCollection new. str := 'This is a string'. str makePersistent. coll1 add: str. coll2 add: str. OmniBase root at: 'one' put: coll1. OmniBase root at: 'two' put: coll2. ] evaluateAndCommitIn: db newTransaction. [ | coll1 coll2 | coll1 := OmniBase root at: 'one'. coll2 := OmniBase root at: 'two'. coll1 first isIdenticalTo: coll2 first ] evaluateIn: db newTransaction.
As you can see the whole expression now evaluates to true. So what's the difference? First let us take a look at how objects are stored in each of these two examples. In the first example the string object was not made persistent on its own. Therefore it was stored as a part of the collection object since it was referenced out of it. Each of the collection objects got their own object id in the database and was stored as a cluster of objects. The following figure shows these two clusters:
As we can imagine when these two objects are later loaded each of them will get its own copy of the string object. However in the second example the objects will be stored as follows:
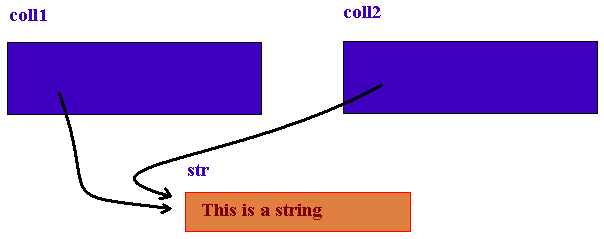
This means that there will be three independent persistent objects (clusters) and that both collections will reference exactly the same string object. Understanding the notion of clustering objects is essential when developing an application with OmniBase since the decision on how to cluster your objects can have very big impact on the scalability and performance of your application.
Probably you have also noticed that we have used message #isIdenticalTo: instead of the usual #==. This is necessary because the database will not load all objects from the database at once. Instead all references to objects which are located outside of the cluster being loaded and were not loaded yet will be replaced by proxy objects. Those proxy objects will catch the first message sent to them and load the real object before forwarding the message to it. Afterwards all messages will be directly forwarded to the underlying object. As you can see the proxy and the real object coexist and both represent the same object. But since they are two objects the usual identity operator #== will not work. That is why you should use the #isIdenticalTo: message for checking identity of objects when using the database. The message #isIdenticalTo: is also clever enough not to load the real object only for checking its identity but instead checks its identity based on its unique oid.
OmniBase uses multi-version concurrency control in order to internally serialize transactions running concurrently. This basically means that a persistent object can have many versions in the database. Each time an object is changed a new version is created in the database. Only after the transaction in which the object has been changed commits, will this new version become visible to every newly started transaction.
Multi-version concurrency control has many advantages compared with traditional approaches where a combination of read and write locks is used to preserve consistency of transaction. The biggest advantage is that long transactions become possible. An example of a long transaction is when a user clicks on an object to open a properties window/pane where the object can be changed. So the transaction would look similar to this:
I we were using read-locks everybody else would not be able to look at the object while it is being edited. But in OmniBase it is still possible to read the object in its consistent state while it is being edited and thus locked for writing only.
Note that we wrote 'to read the object in its consistent state'. This phrase could be best explained with the following example. Let us have an account A and account B and let us transfer an amount from account A to account B:
t1 := db newTransaction. "get account A balance" balanceA := ((t1 root at: 'Accounts') at: 'A') balance. "start another transaction in parallel and make the transfer in transaction 2 " t2 := db newTransaction. accA := (t2 root at: 'Accounts') at: 'A'. accB := (t2 root at: 'Accounts') at: 'B'. accA transfer: 1000 to: accB. newBalance := accB balance. t2 commit. "now get balance of account B" balanceB := ((t1 root at: 'Accounts') at: 'B'.
From this example you can see that although the transaction 1 accessed the account B object after the transaction 2 already committed its changes, the user will still get the object's old value in order to preserve transaction integrity in transaction 1. So in transaction 1 the total amount of money stays the same as in transaction 2 even though the money has been moved from one account to another.
In the example above you can also notice that the value that you are getting from the database may not necessarily be the newest value in the database. To insure you are reading the newest value you can user explicit write locks when needed. The following example show how you could implement a method which would generate unique integer identifiers (counter) in a multi-user environment:
[t := db newTransaction. lastId := t root at: 'lastCustomerId'. t lock: lastId ] whileFalse: [t abort]. lastId increment. t commit. ^lastId
So far we talked only about object locks but there are three levels of locking in OmniBase. These are:
Sorry, this chapter has not been written yet.
Sorry, this chapter has not been written yet.